
I figured out a more or less functional set up for running Stable Diffusion on my Apple M1 MacBook Pro a couple of days ago. Since then, I’ve mostly done Stable Diffusion tasks on my local machine instead of doing things on Google Colab (or Amazon SageMaker Studio Lab).
Working on the local machine, at least for me, gives me more time to think about what I’m doing and to try to improve upon the code. And in the process, I’ve learnt a few things which affect people working on Apple Silicon devices. Plus, I did some improvements to my original code from the first article I linked to above and wanted to talk a bit about that too 🙂
The Stable Diffusion bits from my very first code that I wrote to run on my MacBook looked like this:
device = torch.device("cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu")
pipe = StableDiffusionPipeline.from_pretrained("stable-diffusion-v1-4")
pipe = pipe.to(device)
prompt = "an elf sitting on a toadstool"
image = pipe(prompt)["sample"][0]
You can generate a new image using Stable Diffusion with just five lines (four if you drop the first line and hardcode the device for line 3, or even three if you combine lines 2 and 3). That gets the job done. But keep this code in mind as we progress through the various iterations of the code 🙂
NSFW Images
If you use Stable Diffusion long enough, at some point or other, you’ll get an image which is just totally black. This is generally (but not always) because some word (or words) in your prompt triggered the NSFW (Not Safe For Work) censor.
Now the NSFW censor by itself is not a bad thing. But it can sometimes be confusing as to what is going on if you didn’t know that the black image was due to something in your prompt. Or, if you can’t tell if the black image was due to an NSFW prompt, or if it’s some other issue.
Note: I just got an NSFW alert while testing out some code for this blog post. So if you pay attention, and do run things from the terminal, it appears that you should get at least some warning. But are you paying attention? 😛

If you can’t be bothered to check the terminal output to find out if the image generated was flagged as NSFW, you can also check the result of your image generation. So here’s a modified version of line 3 onwards from above:
pipe = pipe.to(device)
prompt = "an elf sitting on a toadstool"
result = pipe(prompt)
image = result["sample"][0]
is_nsfw = result["nsfw_content_detected"]
The is_nsfw variable in line 5 is a boolean. It tells you whether your prompt triggered the censor or not. So you can simply check that boolean variable and take any necessary action as you see fit.
But what if you didn’t want the censor to be triggered at all? That is easy enough to fix as well 🙂 For the code block above, just add this line after line 1:
pipe.safety_checker = lambda images, **kwargs: (images, False)
The Stable Diffusion pipeline has a small function which checks your generated images and replaces the ones which it deems are NSFW with a black image. The above code simply bypasses the censor. That should fix the issue.
I don’t think I saw any black images since I added the above, but I don’t think I explicitly (no pun intended) tried to invoke the censor either. So I can’t say with 100% certainty that this works (or that it won’t stop working in the future) but at the moment it appears to work based on something I read somewhere …
Batch Processing
The next issue I ran into was getting multiple images generated for the same prompt. Most code samples out there modify line 3 from the second code block above as follows to generate multiple images for the same prompt:
result = pipe([prompt] * 5)
The above works for Apple Silicon macs too … sometimes. Sometimes, especially as the pipeline (and code) gets more complex, it will just barf all over the place like in the image below. (Curiously, this seems to happen when I try for a batch of 2, but not for a batch of 3. I haven’t explored this further to see if this pattern holds for additional values — whether all even numbers cause the crash and odd numbers don’t, for example. Way too many things to do and trying to do batch processing starts my MBP fan to spin way too fast …

Also, and this is the important thing, I haven’t been able to get an actual image generated by using the above method yet 😄 I mean the batching — not the previous code. All I get are either totally black images and NSFW warnings, or images with no distinguishable items in them. If I do the image generation one at a time, it works totally fine. So this might be an Apple Silicon specific bug, a bug due to the patch I implemented originally to fix the Apple Silicon issue, or something else altogether.
If you’re wondering about the code above, it’s simply putting the prompt (which is a string) into an array/list and replicating it five times to get a list that has the same prompt as five separate items/elements.
Since that code didn’t really work on Apple Silicon (it does work on other devices since I’ve seen it work on Google Colab) what I ended up doing finally was to create a loop which ran the image generation multiple times for the same prompt, instead of replicating the prompt multiple times and passing it to the image generator. That worked great.
Here’s the code that I ended up with at this point:
device = torch.device("cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu")
pipe = StableDiffusionPipeline.from_pretrained("stable-diffusion-v1-4").to(device)
pipe.safety_checker = lambda images, **kwargs: (images, False)
prompt = "an elf sitting on a toadstool"
for i in range(5):
result = pipe(prompt)
image = result["sample"][0]
is_nsfw = result["nsfw_content_detected"]
if is_nsfw:
print("NSFW prompt detected!")
image.save(f"sample2_{i}.png")
As a bonus, this code works no matter whether the number of copies is 2 or 5 and it doesn’t seem to make my MacBook heat up as much either 🙂
Image Overwriting
Now that I had multiple images being generated, I realized that when I do a second run of the same script, it overwrites the previous images generated. I am too lazy to keep renaming images and so I decided to go for a slightly better naming scheme. The easiest appeared to be to just use the image generation time.
If I’d been using the batch image generation, this might not have worked so well (at least for saving the image name with the time only up to the second) but since I do the image generation in a loop, it was simple enough to change the naming to use the time at the end of each image generation cycle.
I replaced line 12 in the above code with:
dt = datetime.now().strftime("%d_%m_%Y_%H_%M_%S")
image.save(f"sample_{dt}.png")
You’ll also need to add a from datetime import datetime at the top of the file to make the new code work. This new code saves images with names which look like `sample_04_09_2022_17_35_31.png`. So hopefully, unless you have a really fast machine, you should not have your newer images overwriting older ones any longer.
Of course, this means that you’ll forget about all the images being generated and could end up with a lot of images that you don’t want. But that’s an issue you’ll have to deal with yourself 🙂
Opening Images Automatically
Now that I had the images being generated in batches, I didn’t want to have to open each image by hand — I’m really lazy like that 😛 So I added one more line to the end of the code above to automatically open the image once it is saved:
os.system(f'open sample_{dt}.png')
The above required an import os at the top of the code as well. But that was it. Such a simple change, but it made running long batches of images so much easier since they’d automatically open as each one was generated.
More Changes
I should have been happy with the progress at that point and stopped. But oh no, not me 😛
I decided that since Hugging Face Diffusers has a pipeline to generate not just images from a text prompt, but also one to generate an image based on both a text prompt and an input image, that I was going to implement that pipeline.
All kudos to the fine folks who set up the Hugging Face pipelines because it was so simple to switch over from the text to image pipeline to the image to image pipeline. I don’t think there was that much extra code either.
But do note that at least at this point in time, you might not be able to find the image to image pipeline (StableDiffusionImg2ImgPipeline) as part of the main package if you install the Hugging Face Diffusers via pip. I had to install directly from their repo in order to get the code to work. The command, in case you’re wondering, is:
pip install git+https://github.com/huggingface/diffusers.git
Update: The above is no longer true with the release of Hugging Face diffusers 0.3.0.
Other than that, everything went off without a hitch and I was able to get images generated based on an input image.
But now that I had that, I wanted to switch between text prompts and image input at will. So I added the ability to parse arguments passed to my script so that I can decide which route I wanted to use when generating a new image.
That in turn ended up in me adding support for more Stable Diffusion parameters till I had a fairly versatile image generator which still was pretty svelte at about 140 lines of code or so. I’m not going to post the code here since it’s too long and it probably is something you can figure out yourself, but if anybody wants the code, do let me know and I’ll send it to you. (Or put it up on GitHub.)
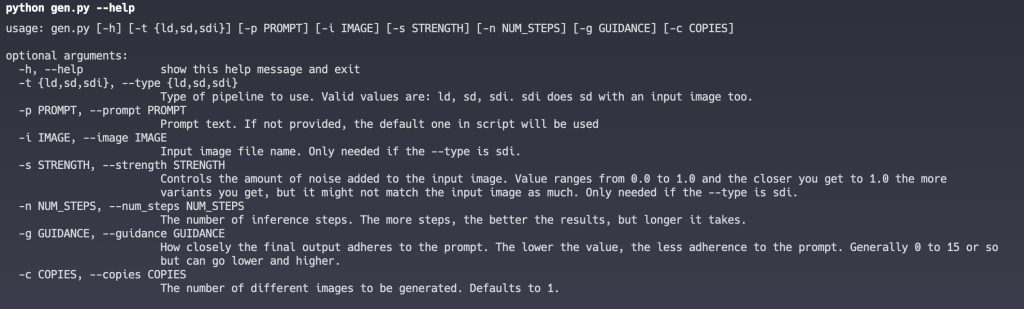
But the final result for the script supported the following parameters:
So did I call it a day at this point? If you thought yes, you don’t know me 😛
Since I was generating so many images, and had multiple parameters being added in at this point, I decided to keep track of the prompt and parameters used to generate each image. So I started saving a text file named sample_xx_xx.txt along with each sample_xx_xx.png file.
But this meant that when I didn’t want a particular image (or multiple images) I had to go through and manually delete multiple files. That would never do!
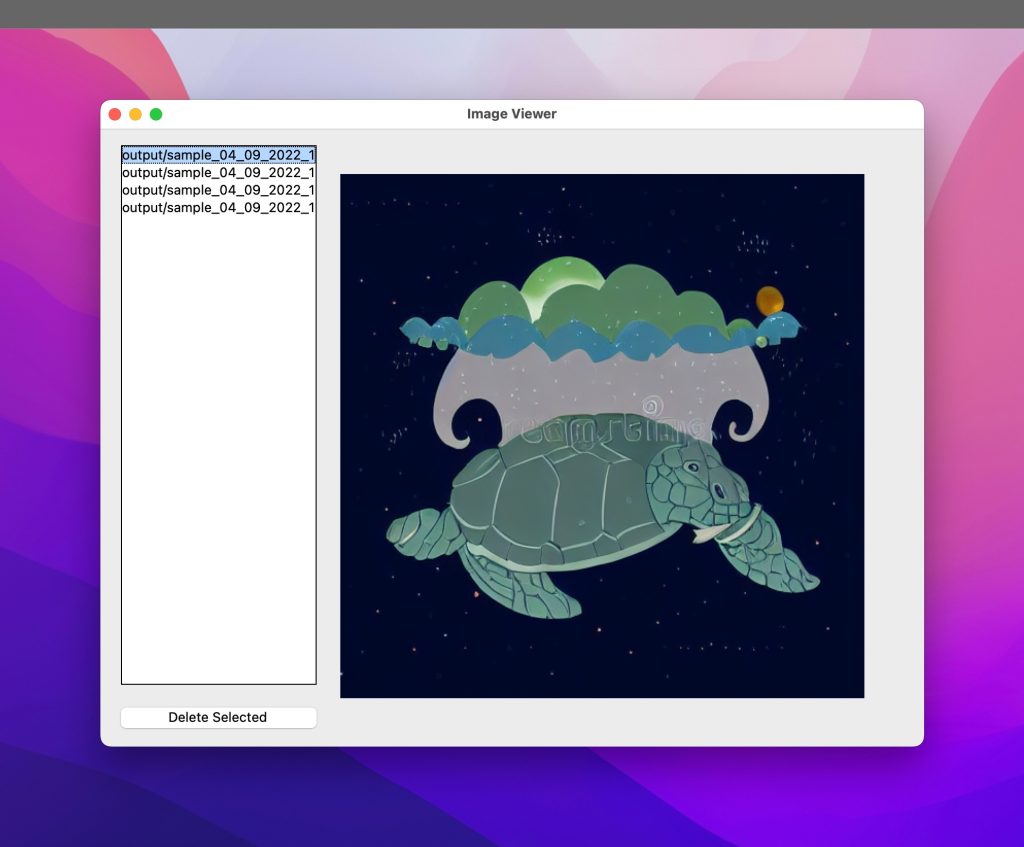
So I added a GUI to display the generated images for each batch so that I could go through the images in the batch at once and delete the ones I didn’t like. And as a bonus, the script would delete the matching prompt info file too.
I looked into using Gradio for the UI since everybody doing a UI for Stable Diffusion seemed to be using Gradio 🙂 But Gradio had a lot of dependencies and, I kid you not, it took at least 10 – 15 seconds to launch on my machine. I just didn’t like the complexity or the long wait and so went really simple and did the UI using tkinter since that comes bundled with Python. So the final result of that phase was this:
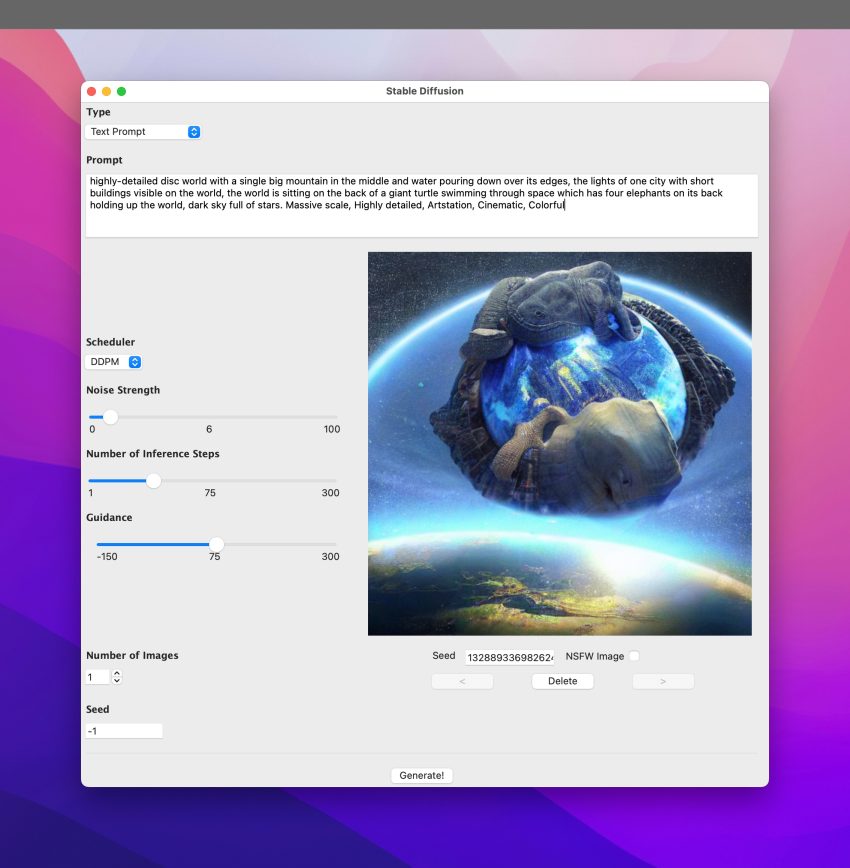
That was yesterday 🙂 Today, I decided that I wasn’t satisfied with just a UI for the end results and I didn’t want to be bothered with passing command-line parameters. So I wanted a full GUI for the app. But I wanted a UI that was a bit complex and I couldn’t be bothered to do all of the UI layout via trial and error — I hadn’t worked with tkinter till yesterday, and didn’t know all the ins and outs.
So I looked at a few GUI layout designers for Python and while there were a couple of decent ones for tkinter, I didn’t like them for one reason or another. So instead, I opted for wxPython, which I hadn’t worked with before either 😛 But what wxPython had going for it was wxFormBuilder, a very nice GUI layout editor which generated Python source code based on the UI you designed visually.
After a day of redesigning the UI, re-working the source code etc. I finally ended up with this:
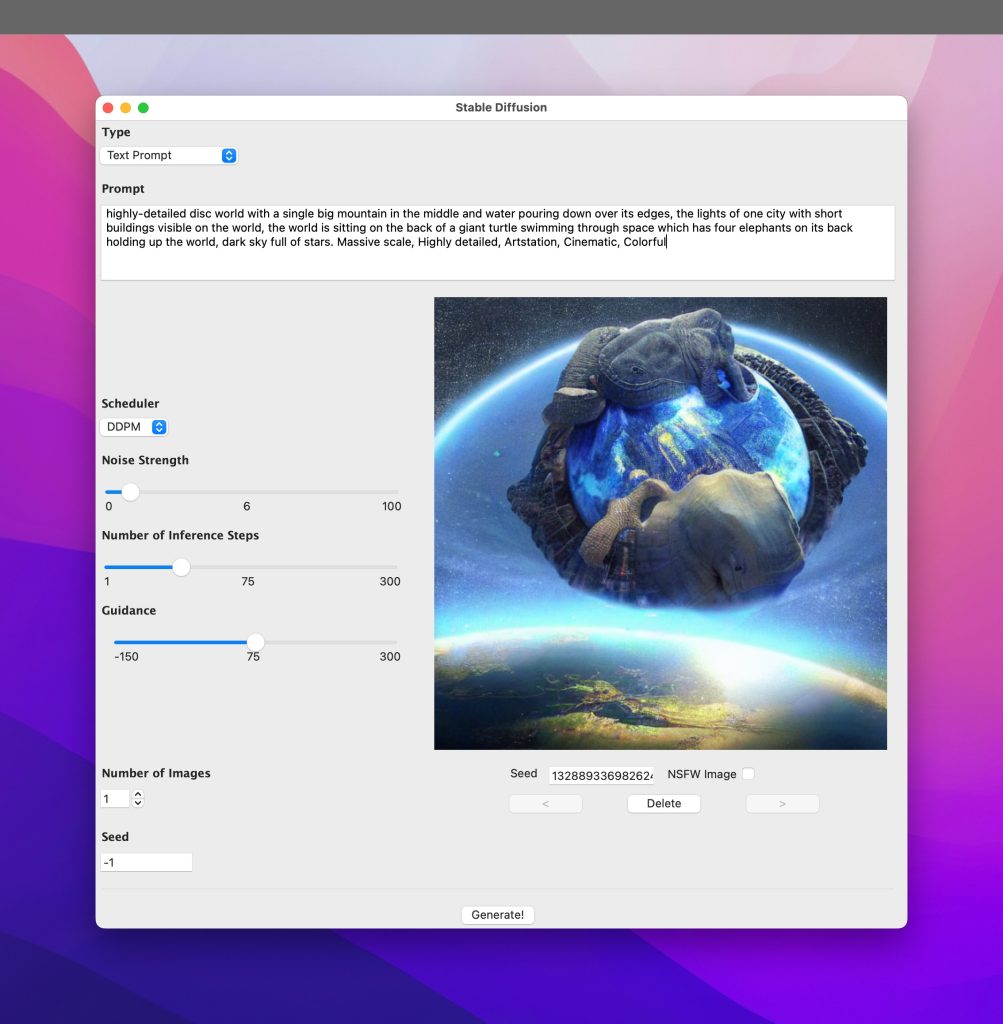
That’s all Python code and still pretty compact at about 400 lines of code in a single file. It could probably do with some refactoring and splitting of code into various files, but I’m happy to leave it as is for the time being just so that I can see the evolution of the code from the initial five or six lines of code to what it is now …
Oh yeah, the Scheduler section has not been implemented yet. It lists around five or six schedulers provided by Hugging Face Diffusers and that’s my project for tomorrow 🙂


Awesome work! Looking forward to seeing how it evolves!
Thanks, Pedro! All this is possible only due to the awesome work you and the others at Hugging Face are doing 🙂 Also, really appreciate how quickly all of you are updating things to work with Apple Silicon. So here’s to the ever evolving adventure!