In my previous post about experimenting with Stable Diffusion, I left out a couple of important things.
The first, is to link to this blog post. It has some excellent info on how to set up Stable Diffusion, how to run it, and the various parameters. In fact, it was the main basis for my own article. So, just citing my sources 🙂
The second is to mention that I used the same seed to generate each of the six images in my output. I didn’t talk about the seed in the previous post and that was my bad. Using a specific seed will ensure that you get the same output from the image generator again. So, using the same static seed values means that I should be able to get the same images again should I wish to do so. You can read more about that in the blog post I linked to in the previous paragraph, if you’re interested.
That said, on to the topic of this article …
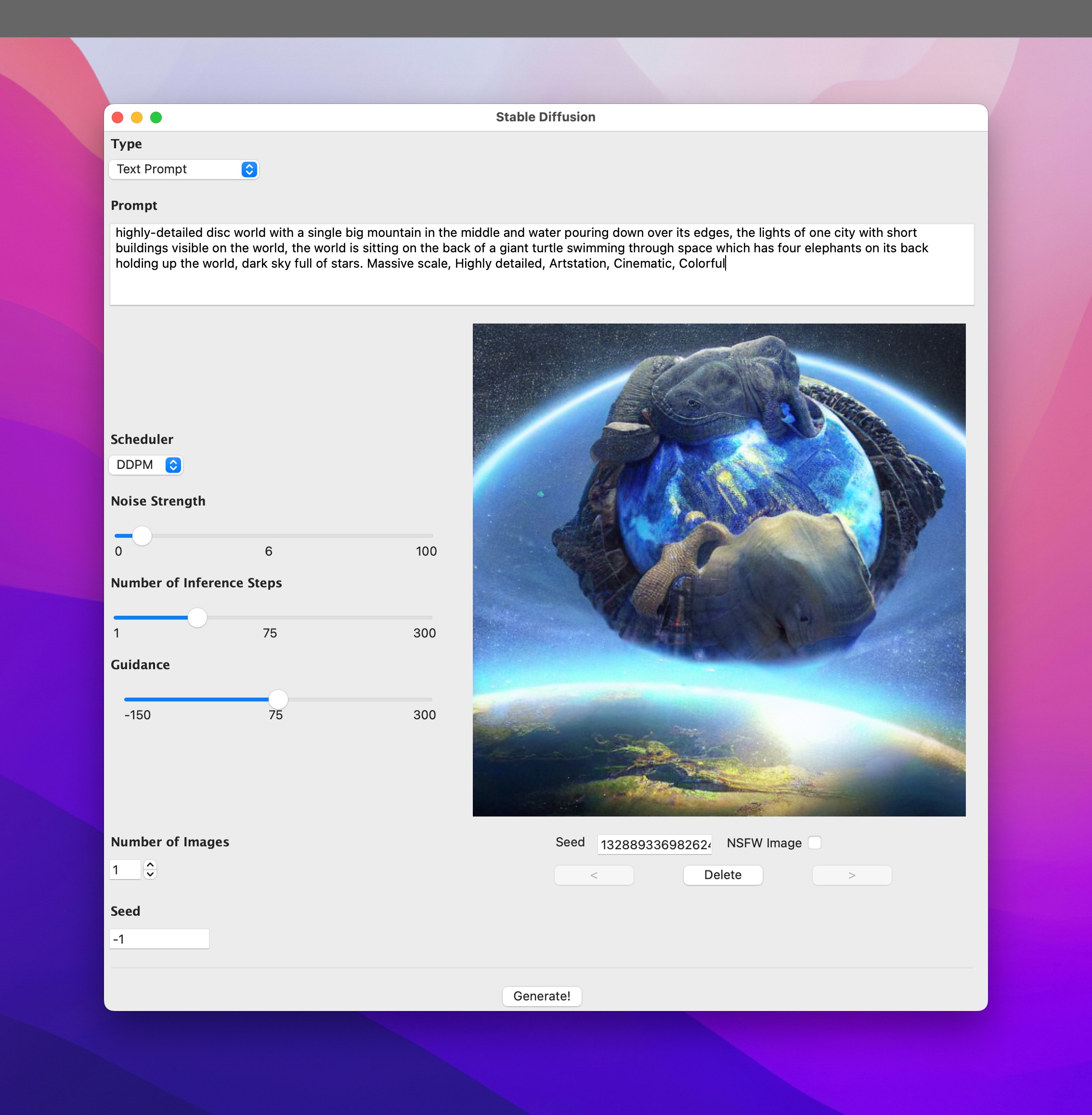
Yesterday, before I began my experiments with the parameters variations, I spent a fair amount of time trying to generate the perfect Discworld image 🙂 Now, just to be clear, this is something I do quite often with image generators. The Discworld, in case you aren’t familiar with it, is a flat disc (hence the name) carried on the backs of four elephants who in turn are standing on a gigantic turtle.
This motif is something which comes from Hindu mythology, by the way. But that’s neither here nor there. What’s interesting is that I’ve not been able to get something that I’d consider even a remote match for “four elephants standing on a turtle’s back and holding up a flat disc world” yet 😛 But I did get some interesting output such as this:



In case you can’t read the captions, I call the first one: Shellephant, and the last: Turtlelephant 😛 There were many others and I gave each variant a different name (but I forget all those names now …) but never did I actually get an image of four elephants on top of a turtle.
This is probably because of the training data used to train this particular model. After all, you normally don’t get a lot of elephants standing on turtles … But, given that this comes from Hindu mythology, some might want to discuss diversity and inclusivity etc … but not me — I’m just interested in giant pachyderms on even bigger chelonians 😛 (Now that’s another prompt that I’d like to try out to see what I get … Hmm …)
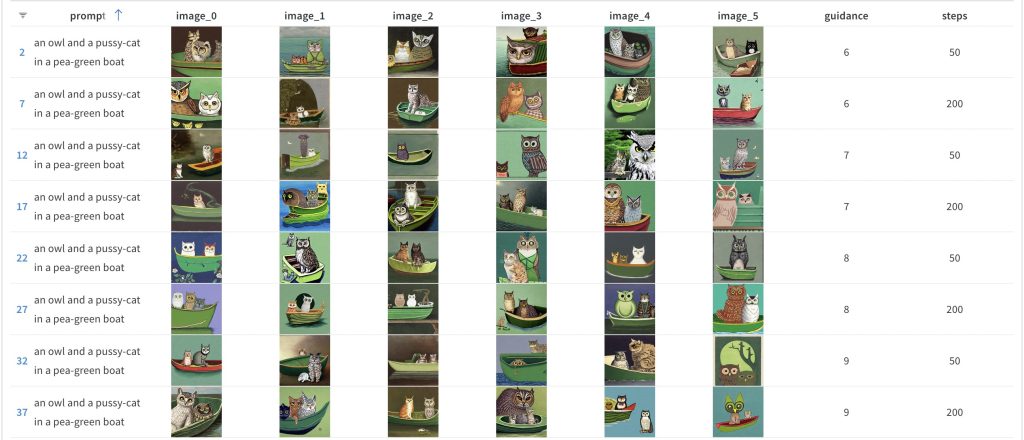
Something similar happened with yesterday’s experiment with various prompts. Three of the prompts worked mostly OK, but two turned out to be difficult children and of those, the most difficult was: “an owl and a pussycat in a pea-green boat”.
I don’t think even a single one of the results from the experiment had a cat in it for the prompt. There were some squiggles and blobs which might have been cats, but they also could have been anything else too 😛
Due to a limitation with the reporting tool I use (or my inexperience with it), I was unable to extract just the owl and the pussycat images from my previous runs. So, I ran the experiment again with the same seeds as yesterday for just this particular prompt. Here’s what I got:
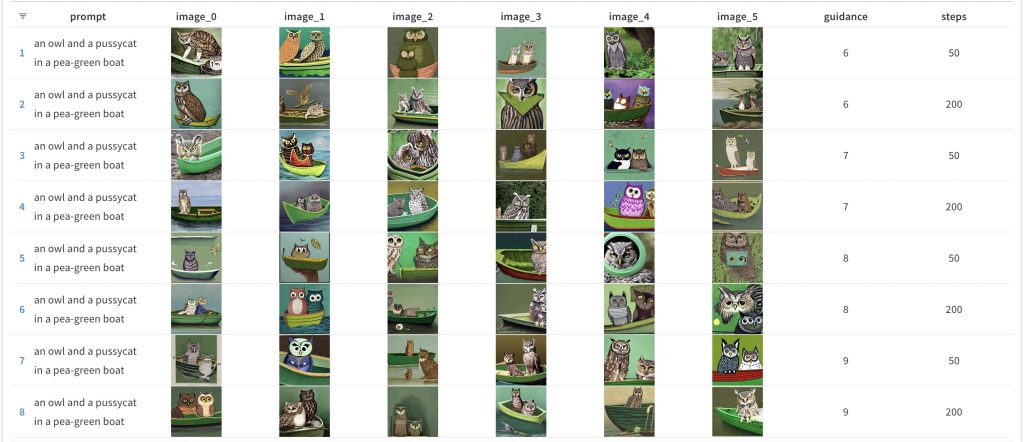
If you were checking to see if the same images appear here as they did in the previous run, you’ll notice that only row 5 is an exact match, but in this case, it matches the results for guidance_scale value of 6 and num_inference_steps of 50. My guess is that this is due to the number of prompts changing for this run, but I’m not absolutely sure. I think I’ll have to do another experiment on that to see what happens …
But, back to the results above. If you look closely, you’ll notice that there are some suspiciously cat-like owls (or owl-like cats) in the images but there are no images of actual cats — at least, not that I could see. But it’s also possible that I missed the one cat which was hiding in the bushes 😛
So what’s going on?
My suspicion is that the culprit here probably is the word “pussycat”. It’s possible that the training data for the model did not have the word “pussycat”. Let’s verify the validity of that theory by using variations on the prompt and seeing what we get …
Here’s the new set of prompts I used:
prompts = [
"an owl and a pussycat in a pea-green boat",
"an owl and a pussy-cat in a pea-green boat",
"an owl and a cat in a pea-green boat",
"a strigine and a feline in a pea-green boat",
"a barn owl and a tom cat in a pea-green boat"
]If you’re wondering why the second prompt is a very minor change (“pussy-cat” instead of “pussycat”), I took a look at the Eward Lear poem and noticed that Lear spelt the word as “pussy-cat”. So I thought I’d try that variation to see what happens 🙂
I’m going to go through the results in the order the prompts appear above. So, here’s the results for the original baseline prompt:

Note: The above image (and all of the following ones) link to the same gallery of images since I combined all the result data into one set. Each page of data in the gallery should be for a particular prompt, but you might have to page around to find the correct prompt. Sorry about that.
As far as the generated images for the initial prompt goes, no surprises there — no “real” cats in sight though there are a couple of instances of owls who might be masquerading as cats 🙂
On to the next prompt:
Apparently adding a hyphen did pay off since we get at least a couple of actual cats and a few more owl-cat hybrids. So are we on the right path?
On to the next one:

Definitely more cats with this prompt, but also … note the weird Batman owl (or maybe it’s a cat masquerading as an owl?) for the 5th image on the first row. No idea what that’s about, but then again, that’s the beauty of AI-based image generation — you never know what you’ll get (so maybe AI image generation is like a box of chocolates? 🤪).
Now we get to stranger territory since I went for a prompt which uses slightly less common words for owls and cats to see what that particular curveball will do. Here’s the results:

Apparently, the model can’t parse (or has not been trained to identify) what a strigine is. So, it’s mostly cats now. There are a few instances where people appear too, especially at higher guidance_scale values. So the guidance_scale setting definitely has some effect — I’d be interested to see what happens if the guidance_scale is increased further …
Finally, something which should be fairly straightforward. The basic prompt for owl and cat but with modifiers for each term:

This one’s mostly what you’d expect — owls and cats. Though there are a few odd ones like the weird worm-like owl on row 4, image_2. But generally, what you’d expect.
So overall, no great surprises here — if the words are common and the prompt is clear, the results generally are what you’d expect. But if you throw in some strange words like strigine and ramp up the guidance_scale value, you might get some interesting results … And if you do, do let me know because I’m interested to see what the AI comes up with 🙂