
All of a sudden, all that anybody seems to talk about when it comes to AI-based image generation is Stable Diffusion from Stability AI. Not that that’s a bad thing, mind you 🙂
Till Stable Diffusion came along, if you wanted to do any image generation using AI, you either had to use the limited (in terms of free) image generation provided by Dall-e or MidJourney, or look at Google’s Imagen and simply hope/wish that one day you would have access to that kind of quality when generating images 😛
Sure, there are other alternatives like Craiyon, but the quality isn’t as good as that of Dall-e or its ilk. Or, if you prefer doing everything on your own, you could get the open source implementations of Imagen such as this one, train your own model and then do image generation on your own machine. Of course, the trouble is that it would take you a very long time to generate a model good enough on a single machine, or even a couple of machines, that you might own.
But all that is behind you now because Stability AI was good enough to release the Stable Diffusion model they trained free of charge — the model was apparently trained for over 150,000 hours (that’s about 410 years BTW) on a large network of 256 computers.
So now you can download the pre-trained Stable Diffusion model and immediately start generating images (well, as soon as you set things up …) without any further delays. It’s as simple as that …
Well, except for knowing how to get the best results from your text prompts …
For example, if you were to use the excellent HuggingFace Diffusers code to get a quick start with Stable Diffusion, you’ll notice that there are multiple parameters that you have to set in order to generate an image based on a prompt. Two of the main parameters that determines the quality/accuracy of the image generated by the code are guidance_scale and num_inference_steps.
The num_inference_steps parameter determines how many inference runs are made based on the prompt to get the final result while the guidance_scale indicates how closely the model should stick to the provided prompt.
But what exactly is the effect of these parameters and how do they affect the generated images? Also, what would be the best values to set for these parameters to get the results you want?
This is what I wanted to find out. So I decided to run a few experiments and compare the results and find out for myself. (Note: the default value set in HuggingFace Diffusers for guidance_scale is 7.5 and num_inference_steps is 50.)
I set up five example prompts:
prompts = [
"a single blood-red rose with thorns dripping blood",
"a flying car against a futuristic city background",
"a cartoon detective",
"a portrait of an astronaut kissing a flower, rembrandt style",
"an owl and a pussycat in a pea-green boat"
]Then I generated six images each for a range of different guidance_scale and num_inference_steps values — 6, 7, 8, and 9 for the former and 50, 100, 150, and 200 for the latter.
As you’ll note, that should result in 16 sets of 30 images each. That’s a lot of images 😛 I’m not sure I would have been able to display all those images in one blog post individually. But I didn’t have to. There’s this very handy service, Weights & Biases, which allows me to send the results of a machine learning job so that I can visualize the results of experiments. And W&B allows me to display the results in very handy grids like the ones below.
So, without further ado, let’s get to the important bit — the results!
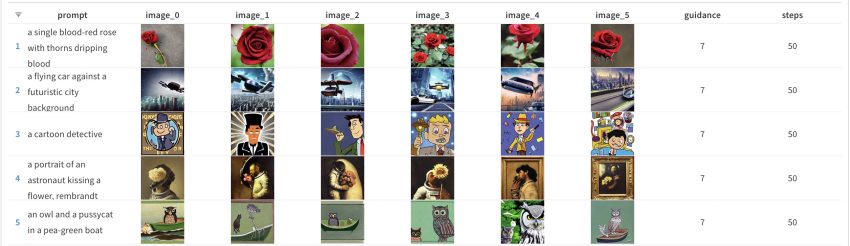
Let’s start with the default values for the parameters that we are looking at. Do note that while the default for guidance_scale is 7.5, I went with whole numbers. So I selected 7 as the default value here. So, for a num_inference_steps value of 50 and guidance_scale of 7, this is the resulting set of images:

Note: The above grid is just an image but if you click on it, you should be taken to a separate page which shows the live report. On that page, do note that you can hover your mouse over an image in the grid and you should see a little “focus” icon. Click on the icon to see a full-size version of each image. That should give you the ability to examine each image as closely as you like 🙂
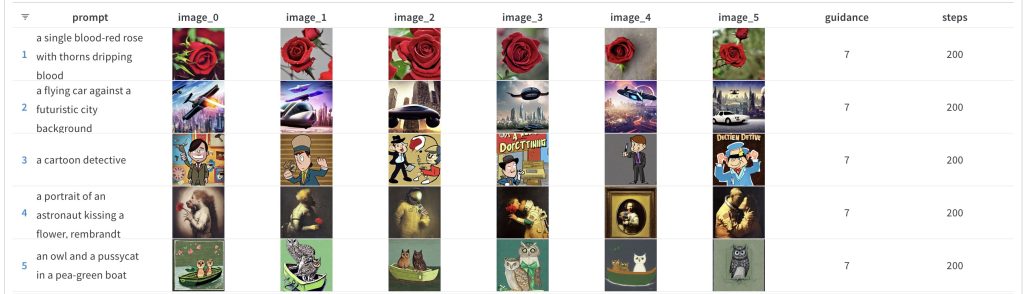
Compare the above to what it looks like when the guidance_scale remains the same (7) but the num_inference_steps goes all the way up to 200:
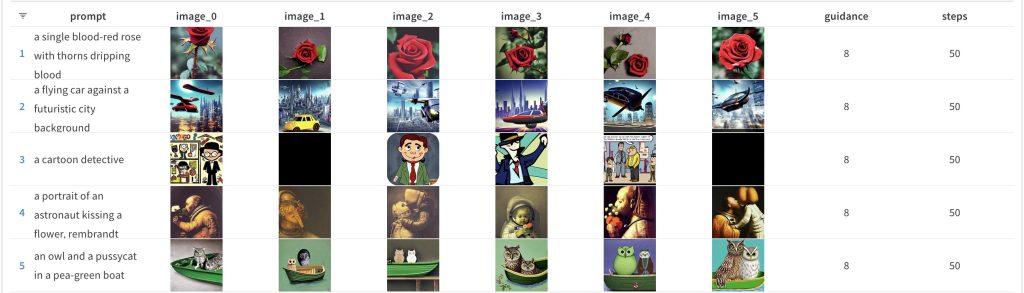
Since the guidance_scale default value is 7.5 and the above is for a value of 7, let us also look at the results for a guidance_scale value of 8:
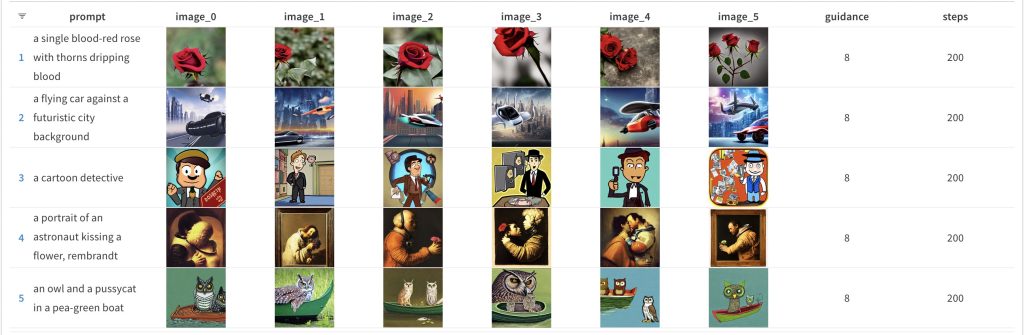
And again the same guidance_scale value but with num_inference_steps bumped up to 200:
Now that we have the default values to compare to, let’s look at the lower end of the test scale — num_inference_steps at 50 and guidance_scale at 6. Here’s what the result looks like:
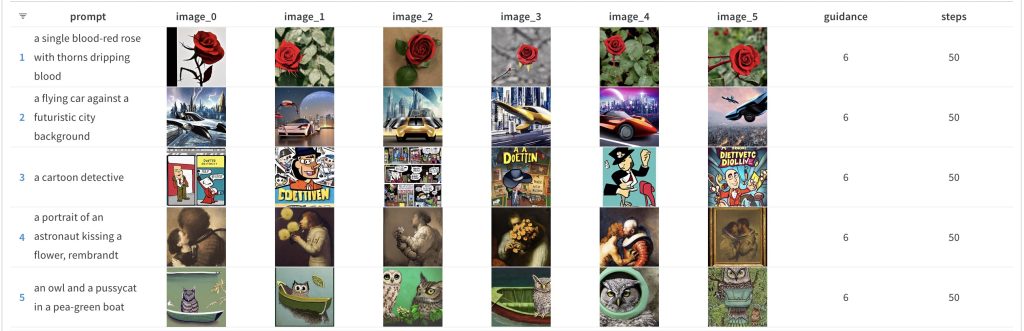
And of course, again the corresponding high num_inference_steps value result:
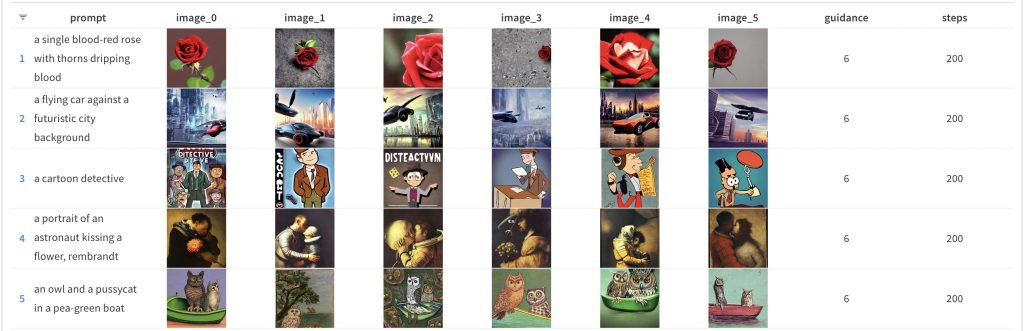
Finally, you have the higher end of the parameter range for the tests — num_inference_steps at 50 and guidance_scale at 9. This is the result:
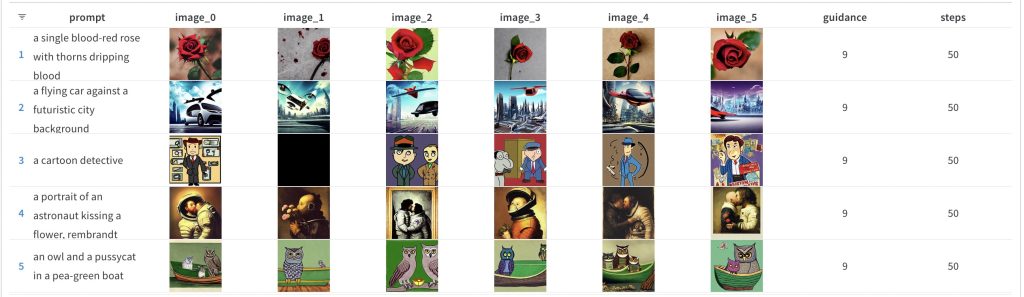
And the corresponding higher end num_inference_steps result:
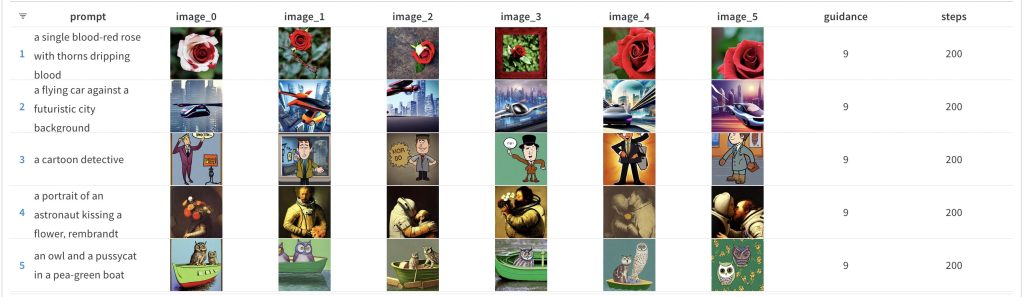
And before you ask, yes, I did leave out the intermediate results — that’s a lot of screenshots to take and reports to prepare 😛 I’ll add those as links below later on …
I’m also thinking of doing two sets of results for guidance_scale set to 5 just for comparison purposes. If I do, will update this post with those too.
But what have we learnt from the above results though?
Personally, (at least with the prompts I used), I don’t see the guidance_scale making too much of a difference at either end of the scale. But maybe that’s just me? But the image quality definitely goes up as you increase the num_inference_steps value.
Also, do note that my prompts resulted in matching images for some cases — especially the owl and pussycat one 😛 I have a feeling that the culprit there is the word “pussycat” and if I had instead used “cat” (without trying to invoke the Edward Lear poem), I probably would have got better results. That’s for another set of tests, I guess …
Speaking of more tests, I’ll have to do more tests to see if these results hold for other implementations using the Stable Diffusion model and also if different prompts makes a difference when using HuggingFace Diffusers. So there’s a lot more stuff to try out and as I do, I’ll post the results here …


