
I’ve always loved words and reading. In fact, some of my earliest memories are of wanting to read but not having the words — once when I was about three and wanting to read a comic in Sinhala and a couple of years later, discovering English comics (TinTin and Marvel comics on two separate occasions) and not knowing English.
I sometimes feel like that these days, when I try to read technical papers on Stable Diffusion and other related areas of deep learning 🙂 Sure, I can read the words, but they (or their meaning) don’t quite make their way to my brain. The jargon and the mathematics kind of blocks the meaning. The thing is, I studied algebra and calculus in school. But that was so long ago that it might as well have been the stone age 😛
In fact, it was the stone age in a way. When I started schooling, they used to write on stone slabs. No, not slabs like these ones in “The Flintstones”:

But more like this:

Since it was made of some type of stone, and you wrote on it with a stone stylus, it still counts, right? 🙂
It’s kind of interesting that I’ve gone from writing on stone slabs to using the same material — silicon — to write in an entirely new medium. But I digress …
The point is that I like reading about the advances in machine learning and sites like arXiv are a great resource because you can see a ton of new papers in a single location. But the papers themselves are hard going for me.
I wished for a way to simplify things so that I can digest the papers more easily. So I figured, why not use deep learning? Sounds like a good idea, right?
I’d been doing some text generation work using GPT-2 and Hugging Face libraries — Hugging Face, incidentally, is a great place to find new deep learning models and how to use them — and I thought why not see if they have a model for text summarization?
They had a ton of them 🙂 I waded through a bunch till I found one I thought might work for me — this one.
I quickly put together a Jupyter Notebook to download a specific paper from arXiv given the paper’s URL, parse the PDF (the downloaded papers are in PDF format — though other formats are available too), and to summarize the text from a range of pages into one short paragraph or to give summaries for each pages separately for a range of pages.
That notebook can be found here in my GitHub repo for FastAI experiments, though this wasn’t strictly a FastAI experiment 🙂 (Incidentally, I’ve been doing a lot of FastAI experiments — their Practical Deep Learning for Coders – Part 2 conducted by Jeremy Howard is fantastic! I’ve been learning a lot and trying out a lot more stuff. Which is why I’ve been forgetting to update this blog recently … I have a lot to write about that experience but that’ll have to wait till another time 🙂)
The final result from my notebook looked like this:
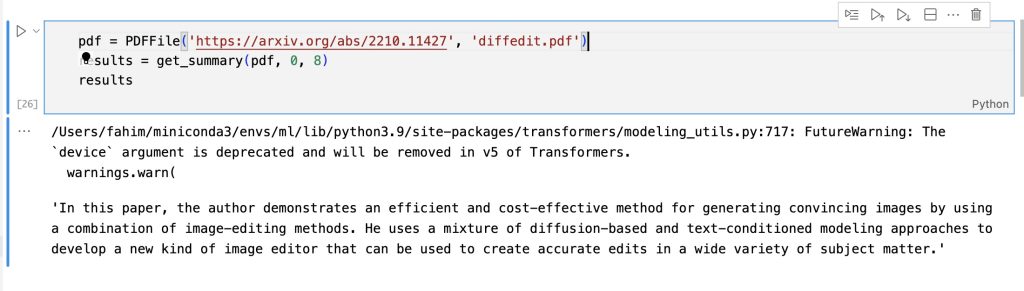
I was excited by the ability to summarize papers easily, and shared it on Twitter and Mastodon, as one does. I didn’t think it was that useful since I figured everybody had a solution like this, or they found reading these papers easier than I did …
But somebody on Mastodon contacted me about it and asked me if I could add a few features to the notebook. On talking to them, it became clear that they were actually looking at a different use-case — being able to summarize a whole bunch of papers so that they can go through a list of new papers on a site and being able to determine which ones are worth reading and which were not.
My code didn’t do that, but it seemed like an interesting project. Also, I’d been hearing about DeepNote and how their Jupyter Notebook environment was so much cooler, and had wanted a chance to try it out. This particular project gave me that opportunity.
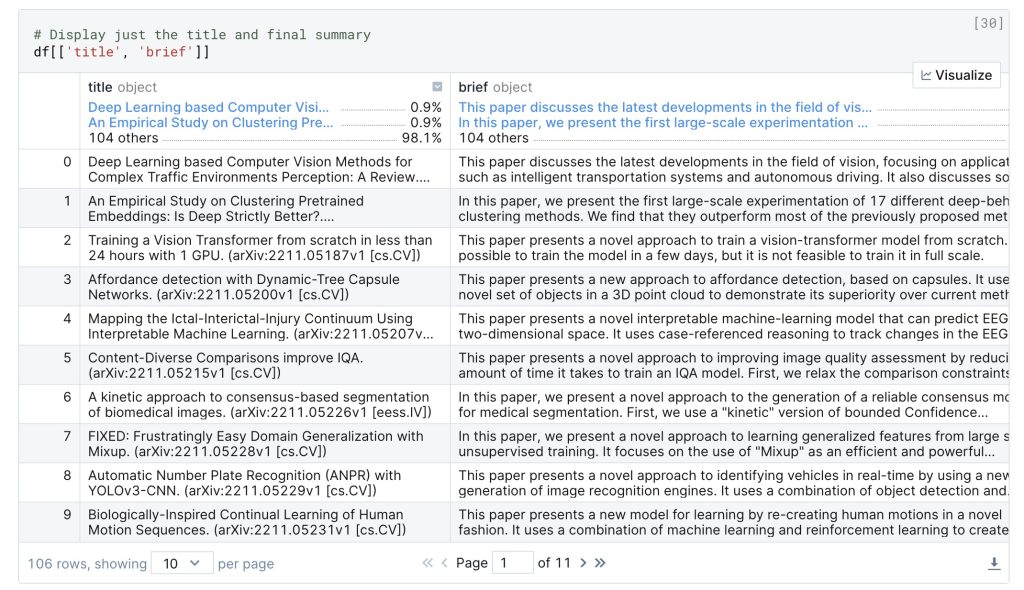
So, I spent a couple of hours putting together code to fetch the RSS feed for a particular category on arXiv — in my case, cs.CV for Computer Vision —, parse the entries, get the summary of the description for each entry and to display a list of titles, authors, and summaries.
DeepNote also allows you to publish your notebooks for others to see. That notebook is here. The final result looks like this:
Job done? Well … not quite.
The above notebook fetched about 100 papers from arXiv but summarizing them took around 2.5 hours on DeepNote. I have not run the process locally and so I don’t know how good the DeepNote hardware is and if I could have done it faster locally or if it would have taken even more time. But the fact remained that it took a long time to process the full RSS feed.
I wanted to reduce that time.
The best option seemed to be to save the fetched list of papers in a local database, and when I next fetched the RSS feed, compare each article against the local DB and see if that article was already in the DB. If it was, I wouldn’t summarize that article again. That way, only new articles would be summarized and the processing time should go down.
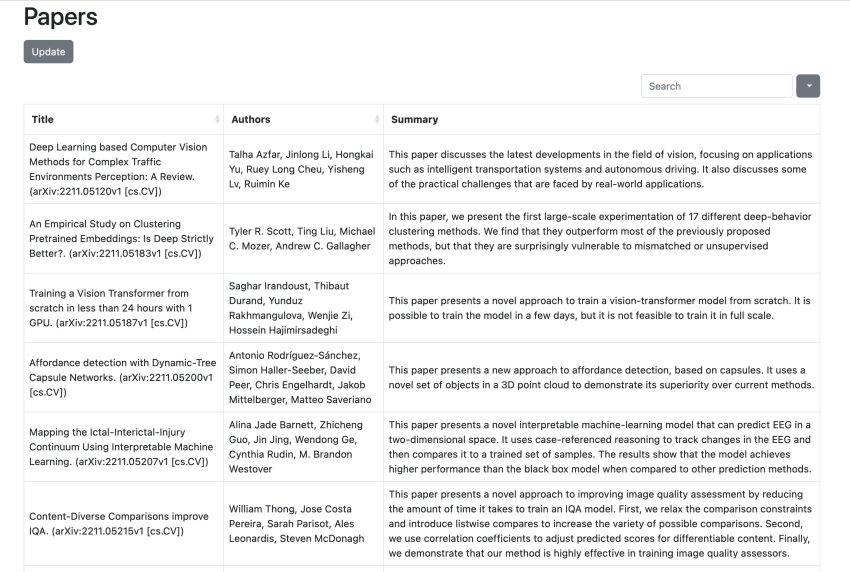
So I set to coding again and after some work, came up with a new Python app. It uses Flask to run a local web server and shows a single web page with a list of articles in the database. Nothing ground breaking, but it does allow you to sort the list by title or author, search for specific words, and to go to the arXiv page for any paper you are interested in just by clicking on the relevant row. It also has a button which will update the database by fetching new articles from arXiv 🙂
The final result looks like this:

I’m pretty happy with where things are, but have plans to add a few more features over the next few days to make it even more useful.
Where can you get it, you ask?
Here 🙂 I put it up as a separate GitHub repo since it’s possible that this project will get additional features/functionality. Or, somebody may be interested in contributing to it. Enjoy!


